Ring Buffer 구조와 Rtsp
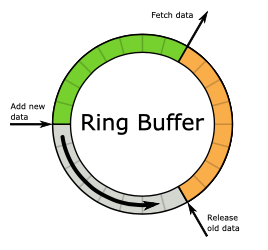
실시간 RTSP 스트리밍을 처리하는 데 있어 1-2초의 지연을 용인할 수 있게 하려면 버퍼를 둘 수 있다. 그리고 그때, Ring Buffer를 활용하면 합리적으로 실시간 요청을 처리할 수 있다.
정의
원형 버퍼(Ring buffer or Circular buffer)는 고정된 크기의 버퍼를 양 끝이 연결된 것처럼 사용할 수 있게 해주는 자료구조이다. 링 버퍼를 이용하면 거의 성능 저하 없이 단순 배열을 덱처럼 사용할 수 있다. (출처: 위키백과)
사용 이유
선입선출(FIFO) 이지만 “쓰기” 한 데이터에 대해 “읽기” 가 발생하면 다음 사이클에 해당 공간을 덮어쓸 수 있다. 즉, 고정된 크기의 버퍼를 쓰지만 write와 read가 적절히 이루어지는 상황에서는 고정된 크기보다 확장된, 공간 효율적인 읽기/쓰기를 할 수 있는 것이다.
- 버퍼를 두는 것은 송수신 속도차가 존재할 때, 고정된 크기만큼의 데이터를 손실없이 보관하고 처리하기 위함임
- 주어진 버퍼를 모두 써서 채운 뒤 동기적으로 일괄된 읽기를 수행하는 기존 버퍼와 달리 유연한 구조
동작

- 시작과 끝 부분이 서로 맞물려 연결돼있는 것이 포인트이다.
예시) 
구현
원형 버퍼는 4개 요소로 보통 구성된다.
- 고정 길이 배열
- read(input) 데이터 위치(index)
- write(output) 데이터 위치 (index)
- empty 여부 flag
요점은 2개의 포인터를 두고 입/출력 (송/수신) 현황을 갱신해나가는 것이다.
예시
RTSP 실시간 영상에 대해 RTSP Writer와 Reader를 만든다.
사전 정보
- SharedMemory에 3차원 numpy 배열을 write하고 read하여 실시간 데이터 전송을 커버한다.
- Writer와 Reader는 각각 프로세스이며 하나의 부모 프로세스로부터 fork된다.
- 공유 메모리 SharedMemory에 대한 access는 Lock을 통해 안전하게 관리된다.
Writer
Writer는 네트워크 연결에 문제가 없는 한 균일하게 FPS 2의 송신 능력을 가진다.
- 초당 2개. 0.5초당 1개 프레임 송신
버퍼 크기가 4인 Ring Buffer를 이용하며 SharedMemory의 index를 돌며 frame을 write한다.
Reader
reader는 주어진 프레임을 활용해 추론 혹은 후처리하는 프로세스로 가정한다. 0-1 사이의 랜덤 값을 가지고 해당 시간마다 하나의 프레임을 처리한다고 가정한다. 평균적으로 처리 시간이 0.5초라고 가정하면 평균처리량 FPS 2
- 최악의 경우 FPS 1 / 최선의 경우 FPS inf
Ring Buffer를 읽고 비어있다면 기다린다.
결과

- Writer가 균일하게 크기가 4인 버퍼에 0.5초마다 프레임을 채워넣는다
- Reader는 대체로 균일하게 read하지만 운이 좋을 때는 빨리 처리하여 주어진 큐를 모두 소모하기도 한다.
- 물론 처음에 큐 크기가 3인 까닭은 운이 안좋아 0.5초보다 느리게 소모하여 큐에 쌓였기 때문이다.

- 심지어 Reader가 빠르게 동작해 모두 소모하고 empty 체크한 뒤 기다리기도 한다.
- 하지만 직후 큐 크기가 2로 다시 늘어나며 다시 축적하게 된다.
의미
링버퍼가 없었다면 Writer의 FPS만큼만 처리하고 나머지 프레임들은 drop 되어 사용하지 않게 된다. Reader가 빠르게 처리할 수 있는 상황에도 Writer가 쌓아놓은 역량이 없으므로 그저 그때그때 존재하는 프레임을 처리할 뿐이다.
하지만 링버퍼가 있다면 얘기가 다르다 예로 Writer의 FPS가 2일 때 Ring Buffer의 크기를 4로 둔다는 것은 2초만큼의 여유공간을 두고 프레임들을 보관하는 것이다. 항상 가장 최근 2초간의 프레임들을 두어 Reader가 더 많은 프레임들을 처리할 수 있게 하여 Frame drop을 줄일 수 있는 것이다.
코드
4개의 코드로 구성된다.
ring_buffer.py
- 링버퍼 구현체 클래스로 SharedMemory에 Write한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
import ctypes
import numpy as np
from multiprocessing import shared_memory
class RingBuffer:
def __init__(
self,
buffer_size: int,
width: int,
height: int,
lock: object,
):
self.buffer_size = buffer_size
self.lock = lock
self.shape = (height, width, 3)
self.read_index_shm = shared_memory.SharedMemory(
name="read_index_shm"
)
self.write_index_shm = shared_memory.SharedMemory(
name="write_index_shm"
)
self.is_empty_shm = shared_memory.SharedMemory(
name="is_empty_shm"
)
self.buffer_shm = shared_memory.SharedMemory(
name="ring_buff_shm"
)
self.frame_id_buff_shm = shared_memory.SharedMemory(
name="frame_id_buff_shm"
)
sample_buffer_queue = np.zeros(
(*self.shape, self.buffer_size), dtype=np.uint8
) # (600768,)
smaple_single_array_list = np.zeros((self.buffer_size), dtype=np.uint64) # (600768,)
# load shm to numpy array
self.read_index = ctypes.c_uint32.from_buffer(self.read_index_shm.buf)
self.read_index.value = 0
self.write_index = ctypes.c_uint32.from_buffer(self.write_index_shm.buf)
self.write_index.value = 0
self.is_buff_empty = ctypes.c_bool.from_buffer(self.is_empty_shm.buf)
# self.is_buff_empty.value = True
self.buffer_queue = np.ndarray(
sample_buffer_queue.shape,
dtype=sample_buffer_queue.dtype,
buffer=self.buffer_shm.buf,
)
self.frame_id_buffer_queue = np.ndarray(
smaple_single_array_list.shape,
dtype=smaple_single_array_list.dtype,
buffer=self.frame_id_buff_shm.buf,
)
def push(self, frame: np.ndarray, frame_id: int) -> bool:
"""
원형 큐에 삽입한다.
항상 해당 위치에 삽입한다.
"""
with self.lock:
# write frame
write_index = self.write_index.value
self.buffer_queue[:, :, :, write_index] = frame
self.frame_id_buffer_queue[write_index] = frame_id
# move write index
self.write_index.value = (write_index + 1) % self.buffer_size
# 비어있지 않은데 read/write 포인터가 같은 곳을 가르키는 경우 read 한칸 전진 (그나마 가장 오래된 것을 읽게한다)
read_index = self.read_index.value
if self.is_buff_empty.value == False and read_index == self.write_index.value:
self.read_index.value = (read_index + 1) % self.buffer_size
# write 이후의 is_empty flag는 반드시 False이다
self.is_buff_empty.value = False
queue_size = int(self.write_index.value) - int(self.read_index.value)
if queue_size < 0:
queue_size = self.buffer_size + queue_size
return write_index, queue_size
RTSP Writer
- opencv를 활용해 RTSP 입력으로부터 frame을 추출해내며 Ring Buffer에 push한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
import time
import cv2
from ring_buffer import RingBuffer
from multiprocessing import Lock
class RTSPWriter:
def init(
self,
url: str,
buffer_size: int,
lock: object,
):
self.lock = lock
self.capture = cv2.VideoCapture(url)
frame_width = int(self.capture.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(self.capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.ring_buffer = RingBuffer(
buffer_size=buffer_size,
width=frame_width,
height=frame_height,
lock=lock,
)
def get_frame(self):
status, frame = None, None
if self.capture.isOpened():
(status, frame) = self.capture.read()
return status, frame
def get_frame_id(self):
frame_id = int(self.capture.get(cv2.CAP_PROP_POS_FRAMES))
return frame_id
def run(
self,
url: str,
buffer_size: int,
lock: object,
interval: int,
):
self.init(
url=url, buffer_size=buffer_size, lock=lock
)
while True:
status, frame = self.get_frame()
# connected
if status is False:
continue
frame_id = self.get_frame_id()
write_index, queue_size = self.ring_buffer.push(
frame=frame, frame_id=frame_id
)
print(f"RTSP Writer | pushed frame_id {frame_id} | write index {write_index} | curr queue_size {queue_size}")
time.sleep(interval)
RTSP Reader
- 주어진 RTSP frame을 처리하는 부분으로 처리부이지만 예제에서는 dummy로 read만 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
import time
import cv2
import ctypes
import numpy as np
import random
from multiprocessing import shared_memory
class RTSPReader:
def init(
self,
url: str,
buffer_size: int,
lock: object,
):
self.buffer_size = buffer_size
self.lock = lock
self.capture = cv2.VideoCapture(url)
frame_width = int(self.capture.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(self.capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
self.shape = (frame_height, frame_width, 3)
self.read_index_shm = shared_memory.SharedMemory(
name="read_index_shm"
)
self.write_index_shm = shared_memory.SharedMemory(
name="write_index_shm"
)
self.is_empty_shm = shared_memory.SharedMemory(
name="is_empty_shm"
)
self.buffer_shm = shared_memory.SharedMemory(
name="ring_buff_shm"
)
self.frame_id_buff_shm = shared_memory.SharedMemory(
name="frame_id_buff_shm"
)
sample_buffer_queue = np.zeros(
(*self.shape, self.buffer_size), dtype=np.uint8
) # (600768,)
smaple_single_array_list = np.zeros((self.buffer_size), dtype=np.uint64) # (600768,)
# load shm to numpy array
self.read_index = ctypes.c_uint32.from_buffer(self.read_index_shm.buf)
self.write_index = ctypes.c_uint32.from_buffer(self.write_index_shm.buf)
self.is_buff_empty = ctypes.c_bool.from_buffer(self.is_empty_shm.buf)
self.buffer_queue = np.ndarray(
sample_buffer_queue.shape,
dtype=sample_buffer_queue.dtype,
buffer=self.buffer_shm.buf,
)
self.frame_id_buffer_queue = np.ndarray(
smaple_single_array_list.shape,
dtype=smaple_single_array_list.dtype,
buffer=self.frame_id_buff_shm.buf,
)
def run(
self,
url: str,
buffer_size: int,
lock: object,
interval: int,
):
self.init(
url=url, buffer_size=buffer_size, lock=lock
)
while True:
with lock:
# empty
if self.is_buff_empty.value is True:
print(f"RTSP Reader | queue is empty. waiting ...")
# there's frame to read
else:
read_index = self.read_index.value
frame = self.buffer_queue[:, :, :, read_index].copy()
frame_id = self.frame_id_buffer_queue[read_index]
self.read_index.value = (read_index + 1) % buffer_size
# read index가 write index를 따라잡았을 경우. 큐가 빈 것이다.
if self.read_index.value == self.write_index.value:
self.is_buff_empty.value = True
print(f"RTSP Reader | read frame_id {frame_id} | read index {read_index}")
# 0-1 사이의 float 무작위값을 interval과 곱하여 상한이 있는 처리 속도를 주어
# 성능이 잘 나오는 상황과 못나와 큐에 쌓이는 상황을 연출한다.
time.sleep(interval * random.random())
main
- multi-processing 구조의 부모 프로세스이다.
- main.py 에서 Writer process와 Reader process를 자식 프로세스로 구동한다.
- 둘 사이에서 공유 자원 관리는 multiprocessing.Lock으로 수행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
import ctypes
import cv2
import numpy as np
from multiprocessing import shared_memory, Lock, Process, set_start_method
from rtsp_reader import RTSPReader
from rtsp_writer import RTSPWriter
def create_shared_memory(url: str, buffer_size: int):
capture = cv2.VideoCapture(url)
frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
shape = (frame_height, frame_width, 3, buffer_size)
sample_ring_buff = np.zeros(shape, dtype=np.uint8) # (600768,)
try:
shm = shared_memory.SharedMemory(name="ring_buff_shm")
shm.unlink() # 공유 메모리 삭제
except FileNotFoundError:
print(f"ring_buff 공유 메모리가 이미 삭제되었습니다.")
finally:
shared_memory.SharedMemory(
name="ring_buff_shm",
create=True,
size=int(sample_ring_buff.nbytes),
)
try:
shm = shared_memory.SharedMemory(name="read_index_shm")
shm.unlink() # 공유 메모리 삭제
except FileNotFoundError:
print(f"read_index_shm 공유 메모리가 이미 삭제되었습니다.")
finally:
shared_memory.SharedMemory(
name="read_index_shm",
create=True,
size=ctypes.sizeof(ctypes.c_uint32),
)
try:
shm = shared_memory.SharedMemory(name="write_index_shm")
shm.unlink() # 공유 메모리 삭제
except FileNotFoundError:
print(f"write_index_shm 공유 메모리가 이미 삭제되었습니다.")
finally:
shared_memory.SharedMemory(
name="write_index_shm",
create=True,
size=ctypes.sizeof(ctypes.c_uint32),
)
try:
shm = shared_memory.SharedMemory(name="is_empty_shm")
shm.unlink() # 공유 메모리 삭제
except FileNotFoundError:
print(f"is_empty_shm 공유 메모리가 이미 삭제되었습니다.")
finally:
shared_memory.SharedMemory(
name="is_empty_shm",
create=True,
size=ctypes.sizeof(ctypes.c_bool),
)
try:
shm = shared_memory.SharedMemory(name="frame_id_buff_shm")
shm.unlink() # 공유 메모리 삭제
except FileNotFoundError:
print(f"frame_id_buff_shm 공유 메모리가 이미 삭제되었습니다.")
finally:
shared_memory.SharedMemory(
name="frame_id_buff_shm",
create=True,
size=ctypes.sizeof(ctypes.c_uint32),
)
if __name__ == "__main__":
set_start_method(method="fork", force=True)
# set common setting values
sample_url = "rtsp://210.99.70.120:1935/live/cctv001.stream"
buffer_size = 10
lock = Lock()
create_shared_memory(
url=sample_url,
buffer_size=buffer_size
)
rtsp_writer = RTSPWriter()
rtsp_reader = RTSPReader()
writer_process = Process(
target=rtsp_writer.run,
kwargs={
"url": sample_url,
"buffer_size": 4,
"lock": lock,
"interval": 0.5,
}
)
writer_process.daemon = False
reader_process = Process(
target=rtsp_reader.run,
kwargs={
"url": sample_url,
"buffer_size": 4,
"lock": lock,
"interval": 1,
}
)
reader_process.daemon = False
reader_process.start()
writer_process.start()
reader_process.join()
writer_process.join()
+ Lock의 위험성
while loop을 수행하며 지속적으로 Critical section에 진입하려하는 spin lock은 성능을 저하시킬 수 있다. cpu utilization이 80% 이상으로 높지만 실질적인 처리 능력이 떨어질 때는 lock을 의심해 봐야 한다.
cpu가 Ring Buffer로 합리적으로 큐에 쌓인 숙제들을 처리하느라 바쁜 것이 아니라 Lock을 먼저 잡기 위해 열심히 확인하는 경우일 수 있다.
위 경우 Single Buffer로 변경하고 SharedMemory로는 1bit flag를 하나 두어 Lock없이 비트를 판별해 자원을 사용하면 더 좋은 결과를 낼 수도 있다.