Cpu Pinning과 Numa 구조
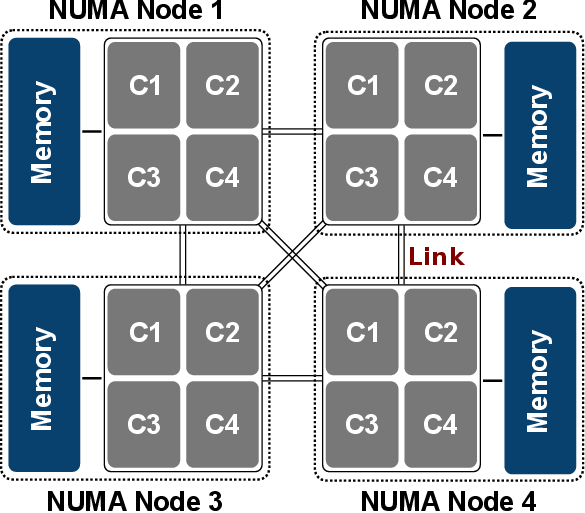
보통은 성능을 높이기 위해서 소프트웨어 코드를 효율적으로 리팩토링 한다. 그러나 근본적인 하드웨어의 제약을 검토하는 것 또한 필요하다.
발단
실시간으로 이미지를 처리하는 프로젝트를 진행하는데 성능이 너무 안나왔다.
병목구간을 찾다 찾다 하드웨어단에서 cpu와 gpu 사이에 데이터를 운반하는 메모리 버스를 의심하게 되었다.

왜냐하면 나는 위 사진과 달리 CPU가 2개였고 GPU는 분명 하나의 CPU에만 연결돼있을 것이다.
그렇다면 GPU는 본인과 가까운 곳에 PCI Bus로 연결돼있을 것이고 만일 먼 곳의 CPU를 할당하면
프로세스는 더 빠른 길이 있음에도 조금 더 돌아갔다 와야 하는 것이다.
NUMA(Non Uniform Memory Access)
다수의 CPU 프로세서들이 메모리와 I/O를 나란히 공유하여 병목을 일으킬 수 있는 UMA(Uniform Memory Access)에서 발전한 NUMA 구조이다.

각 CPU 프로세서가 독립적으로 각자의 메모리 공간을 갖기 때문에 UMA와 다르게 줄을 서지 않아도 되고
병목없이 빠르게 메모리에 접근할 수 있다.
위 그림에서 NUMA Node 2에 GPU가 붙어있다고 가정해보자.
2번 노드의 코어들로 딥러닝 이미지 처리 연산을 하면 다음 동작이 일어난다
- cpu에 이미지를 올린다.
- gpu에 이미지를 복사하고 처리한다.
- 결과를 cpu로 전달한다.
위 과정이 반복되며 cpu-gpu 데이터 전달이 많이 일어날 것이다.
그런데 만약 이 프로세스를 다룬 NUMA Node 1, 3, 4 에서 수행한다고 생각해보자
GPU를 쓰려면 NUMA Node 2와 연결된 PCI bus를 통해 통신해야한다.
“CPU 1 - CPU 2 - GPU” 처럼 한다리 건너갔다오니 비효율적이고 속도 저하를 발생시킨다.
NUMA Node 확인하는 법
내 GPU가 어느 CPU에 붙어있는 지 확인할 수 있다.
1
2
3
4
5
# nvidia 그래픽카드이고 1개만 있어 GPU가 0번에 위치한 경우
$ nvidia-smi topo -C -i 0
# result
NUMA IDs of closest CPU: 1
위와 같다면 NUMA Node 1번인 것이다.
CPU 정보 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 143
Model name: Intel(R) Xeon(R) Gold 6426Y
Stepping: 8
CPU MHz: 4100.000
CPU max MHz: 4100.0000
CPU min MHz: 800.0000
BogoMIPS: 5000.00
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 2048K
L3 cache: 38400K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hfi avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
NUMA node는 0번과 1번 2개가 있고 각 CPU가 가진 프로세서의 번호들이 나열된다.
위 장비에는 소켓이(cpu) 2개이며 한 소켓에는 16개의 코어가 있고 각 코어는 2개씩 스레드를 갖는다.
그래서 2 * 16 * 2 프로세서가 총 64개 있다.
프로세서 할당
멀티 프로세스 환경에서 GPU를 사용하는 프로세스들에게는 GPU와 가깝게 연결된 NUMA node cpu 프로세서들을 할당해 주는 것이 궁극적 목적이다.
위에서 구한 정보들을 종합하면 NUMA Node 1번에 해당하는
1
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63
위 프로세서들을 할당하면 되겠다.
import os
pid = os.getpid() # 현재 자식 프로세스의 PID
cpu_cores = [1,3,5,7,9]
os.sched_setaffinity(pid, set(cpu_cores)) # 자식 프로세스를 특정 논리적 CPU에 고정
결론
위처럼 gpu가 사용하는 cpu를 특정해주고 CPU 프로세서들을 할당하였을 때 성능 향상을 얻을 수 있었다.
나는 1 FPS 정도이던 초기 성능을 2~3 FPS 정도로 2배 이상 끌어올릴 수 있었다.
+개발자는 소프트웨어적인 문제를 의심하기 마련이다. 이번 기회에 이렇게 low level로 접근해서 문제를 해결한 경험이 생겨서 기분이 좋다. 항상 근본적인 걸림돌이 없을 지 의심해보자